Too little, too slow
An introduction to memory management
and
Linux memory management today and tomorrow
Rik van Riel
Conectiva S.A. http://www.conectiva.com/
riel@conectiva.com.br
Generated from the Magicpoint slides 27/nov/2000
(page 1)
Too little, too slow
- Memory hierarchy
- Caches
- mapping, associativity, coherency
- Main memory
- virtual memory, virtual -> physical mapping
- page faults, page replacement
- Disk
- performance characteristics
- HSM
- Something on Linux VM in 2.2, 2.4 and 2.5
- how it (doesn't) work(s)
- how to fix things
- emergency fixes for 2.4
- stuff we want/need in 2.5
(page 2)
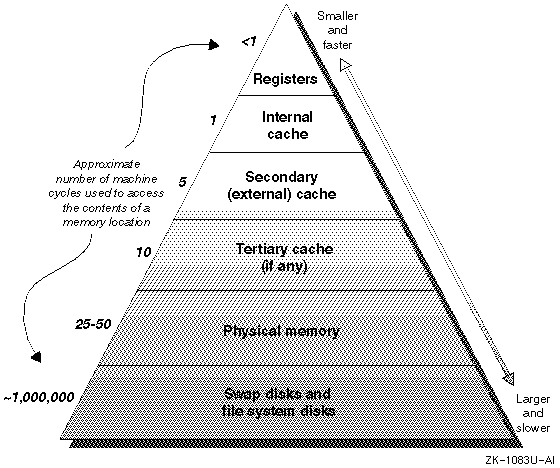
Memory hierarchy
(page 3)
Memory hierarchy: basics
- The hierarchy exists because
- fast memory is expensive and has to be small
- slow memory is cheap and can be big
- Latency
- how long do I have to wait for the data?
- (cannot do anything while waiting)
- Throughput
- how many MB / second?
- not important when you're waiting
- Total time = latency + (amount of data / throughput)
(page 4)
Memory hierarchy: who does what?
- CPU core
- programmed by the programmer
- speed optimisations mostly invisible
- L1, L2 (and L3) cache
- managed by the hardware
- invisible, except for speed differences
- RAM
- managed by the OS
- RAM management invisible for user applications
- Disk
- managed by the OS
- programs open files, read / write data, etc.
(page 5)
Memory hierarchy: numbers
Below is a table with some "randomly" chosen CPU types and their L1 and L2 cache
characteristics. The exact numbers are not very important, but it is good to realise
that even the L2 cache is not fast enough to let the CPU core run at 4% of its maximum
speed...
| Cache size & speed vs. CPU model |
Celeron A |
PIII |
Athlon |
K6-III |
| L1 size |
32kB |
32kB |
128kB |
64kB |
| L2 size |
128kB |
512kB |
512kB |
256kB |
| L1 lat |
3 |
3 |
3 |
2 |
| L2 lat |
8 |
24 |
21 |
11 |
| L2 total |
11 |
27 |
24 |
13 |
| L1 ass. |
4 |
4 |
2 |
2 |
| L2 ass. |
8 |
4 |
2 |
4 |
As you can see, RAM and hard disk speeds are so rediculously low that you must avoid
RAM and disk access at all cost if you want performance.
RAM latency: 50 - 400 cycles
Disk latency: > 3.000.000 cycles
(page 6)
Memory hierarchy: working set
- Why do we still have performance?
- locality of reference
- most accesses in a small part of memory
- most data rarely accessed
- just accessed data often used again soon
- predictable access patterns
Of course this breaks in applications that don't exhibit good locality \
of reference. Luckily it works well for most programs.
(page 7)
Cache
- L1 cache
- closest to the CPU
- fast
- simple
- small (16 - 128kB)
- separate instruction and data caches
- L2 cache
- between L1 cache and memory
- larger then L1 cache (128kB - 8MB)
- more complicated
- slower
- unified cache
(page 8)
Cache: how it works
- Cache strategies
- cache line
- mapping
- direct mapped
- N-way set associative
- fully associative
- replacement
- (direct mapped)
- LRU
- semi-random
- write strategy
- write through
- write back
- write around
(page 9)
Cache: dirty memory
- When the CPU writes out a value
- we cannot just forget about it
- it has to be written to (slow) memory
- Who writes back
- write through
- write back
- cache writes back the data
- cpu can do something else at the same time
The fastest way of getting a cache line replaced is by not writing \
to it, so we CAN just forget about it when we need to cache something \
else.
(page 10)
Cache: coherency
We must make sure that we won't write stale data to disk or work on \
stale data from another CPU.
- Strategies
- selectively flush the cache
- use uncached memory for certain things
- don't allow shared data
- MESI (modified, exclusive, shared, invalid)
(page 11)
Cache: program optimisation
This example is from the Linux kernel source code, from \
kernel/sched.c::reschedule().
When all running processes have used their time slice:
- p->counter == 0 for running processes
- we recalculate p->counter for all processes
- for most processes, p->counter will not change
recalculate:
for_each_task(p)
p->counter = (p->counter >> 1) + p->priority;
(page 12)
Cache: program optimisation
The magic trick:
recalculate:
for_each_task(p)
p->counter = (p->counter >> 1) + p->priority;
recalculate:
for_each_task(p) {
if (p->counter != (p->counter >> 1) + p->priority)
p->counter = (p->counter >> 1) + p->priority;
}
(page 13)
RAM
- Main memory
- slowest volatile memory
- fairly big (32MB - 8GB)
- management is not done by hardware, but by the OS
- complex memory management is worth it
- ram is 100 x slower than cpu core
- ram is 100.000 x faster than disk
- allocation granularity in pages (4 to 64kB)
- (128 x bigger than a cache line)
(page 14)
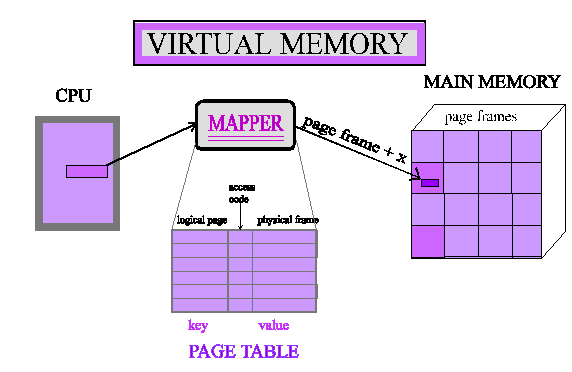
RAM: virtual memory
- Virtual memory
- can use more address space than available memory
- can run more programs than fit in memory
- every process has its own "virtual" address space
- processes cannot access each other's memory
- processes do not have to know about each other
- page 0 in one process is NOT page 0 in another process
- not all pages of a program have to be in memory
- page faults
- virtual -> physical mapping
(page 15)
RAM: virtual memory
(page 16)
RAM: virt -> phys mapping
- MMU
- Memory Management Unit
- does the translation
- TLB
- Translation Lookaside Buffer
- cache for the MMU translations
- Page tables
- index of which process (virtual) address is where in physical memory
- often multi-level page tables
- If an address is not in the TLB
- hardware lookup by MMU (x86, m68k)
- software lookup by OS (MIPS, Alpha?, PPC)
(page 17)
RAM: page faults
- If a page isn't in memory
- processor traps with a PAGE FAULT
- OS gets the error and the job of fixing it
- grab a page from the free list
- read in the data from disk (if needed)
- write the page table entry
- let the program continue from where it aborted
- the process continues like nothing has happened
- transparent (the process never sees the page fault)
- slow (because disk is very very slow)
- if the system gets low on free memory
- make more free pages
- chose the right page to evict/replace/page out/...
Because a page fault is very Very VERY slow, we really want to \
minimise the amount of page faults.
(page 18)
RAM: page replacement
- If free memory is low, chose a page to free
- perfect page replacement
- evict the page that will not be used again for the longest time
- if you do that every time, the number of page faults is minimal
- optimal
- violates fundamental law of nature
- Least Recently Used (LRU)
- evict the page that hasn't been used for the longest time
- very good for some situations
- absolute worst-case for some other (common) situations
- streaming IO
- working set just over memory size
- high overhead
- Least Frequently Used (LRU)
- evict the page that has been used the least often
- very slow to adopt to changing workload
- high overhead
- LRU approximations
- evict any page which hasn't been used for a long time
- simple
- low overhead
- good enough
(page 19)
RAM: LRU approximations
- NRU
- not recently used
- very rough LRU approximation
- idea: don't evict pages which were just used
- NFU
- not frequently used
- keep pages which have been used often in memory
- idea: don't evict pages which are used over and over again
- Page aging
- combines good points of NRU and NFU
- relatively low overhead
- used in Linux 2.0, FreeBSD and Linux 2.4
- when a page is used, increase page->age
- page->age += MAGIC_NUMBER
- when a page is not used, decrease page->age
- page->age -= ANOTHER_MAGIC_NUMBER
- page->age = page->age / 2
- remove page from memory when page->age reaches 0
(page 20)
RAM: other replacement tricks
- Drop behind
- with streaming IO, data is usually only used once
- deactivate the data behind the readahead window
- page is still in the inactive list if needed again soon
- Idle swapout
- for swapout, first look at long sleeping processes
- less chance of evicting a used page from a running process
- we swap out idle processes before eating too much from the cache
- less overhead, you don't find recently accessed pages in a process that
has been sleeping for 10 minutes
(page 21)
Disk
- Hard disk
- persistant storage
- stored on disk
- executable code
- system configuration
- program and user data
- metadata (an index of what is where)
- swapped out memory
- big and cheap (2GB - 100GB)
- 100.000 x slower than memory
- "interesting" performance characteristics
- high throughput (fast)
- extremely long seek times (slow)
- RAID and/or smart controllers make latency unpredictable
(page 22)
Disk: performance characteristics
- disk consists of
- spinning metal plates with oxide surface
- disk arms with read/write head
- latency
- seek time
- rotational delay
- queue overhead
- 5 - 15 milliseconds (100.000 x slower than RAM)
- throughput
- density
- rotational speed
- higher near edge of disk, less near the center
- 5 - 40 MB / second (10 x slower than RAM)
(page 23)
Disk: performance optimisations
How to get disk performance good?
- readahead
- we read in the data before it is needed
- the program doesn't have to wait
- we waste some memory, possibly evicting useful data
- reduce the amount of disk seeks
- smart filesystem layout
- metadata caching
- I/O clustering
- read large blocks of data at once
- less seek time per MB transfered
- don't access the disk
- caching of data
- smart page replacement algorithm (RAM)
- read the data before it is needed
- RAID
(page 24)
Disk: RAID
- Redundant Array of Inexpensive Disks (RAID)
- data is spread out over multiple disks, often with parity
- store the data on (for example) 4 disks
- use an extra disk to store "extra" data
- bigger than a single disk
- more reliable
- if a disk fails, we recalculate the "missing" data from the data
we still have and the data on the extra disk
- faster
- you have multiple disks to read the data from
- cheaper than a Single Large Expensive Disk
- continues to work if a single disk fails
- people can continue their work
- no waiting for (old) data on backup tapes
(page 25)
HSM: beyond disk
- Hierarchical Storage Management (HSM)
- data silos (tapes + tape robots)
- disks to cache the data from tape
- used for very large amounts of data
- > 1 TB of data, up to multiple PB (1Mi GB)
- backups take too long
- after a 4-day backup, you have backed up old data
- waiting 4 days to restore the data is not an option
- cheaper and more reliable than disk
- HSM is used for
- meteorological data
- astronomical observations
- particle accellerator measurements
- big (multimedia) data banks
(page 26)
Too little, too slow
Conclusions of the introduction
- faster memory is more expensive and smaller
- every type of memory is too little or too slow
- good locality of reference improves performance
- programs can be optimised for good locality of reference
- programmers can easily mess up performance
- hardware manages L1 and L2 cache
- the OS manages RAM and disk
- smart RAM management minimises disk use
- disk are fast on throughput and very slow on latency
- smart filesystem layout, I/O clustering and RAID maximise disk performance
(page 27)
Linux Memory Management
- Linux VMM
- different types of physical pages (zones)
- ZONE_DMA, ZONE_NORMAL, ZONE_HIGHMEM
- virtual page use
- page and swap cache
- shared memory
- buffer memory
- 2.2 VM
- do_try_to_free_pages
- strong and weak points of 2.2 VM
- needed changes in 2.4 VM
- balanced page aging, multiqueue VM
- optimised page flushing
- plans for 2.5 / 2.6 VM
- out of memory handling / QoS issues
(page 28)
Linux VM: physical zones
- ZONE_DMA
- memory from 0 to 16MB
- can be used for ISA DMA transfers
- can be used for kernel data structures
- can be used for user memory
- ZONE_NORMAL
- memory from 16 to 900 MB
- can be used for kernel data structures
- can be used for user memory
- ZONE_HIGHMEM
- memory > 900 MB
- can be used for user memory
- highmem pages need to be copied to/from normal memory for \
actions like swapin and swapout
On x86 the zones happen to be "inclusive", but this is not the case for \
some other architectures (eg. with NUMA-like setups).
(page 29)
Linux VM: virtual page use
- mapped pages
- mapped in process page tables
- shrunk by swap_out()
- placed in other cache
- pagecache & swapcache
- pages here can be mapped too
- caches parts of files and/or swap space
- shrunk by shrink_mmap()
- in 2.2, cannot hold dirty pages
- shared memory
- SYSV or POSIX shared memory segments
- processes can and unmap map these segments
- swapped out with shm_swap()
- buffer cache
- cached disk data that doesn't fit in the page cache
- buffer heads map the data to a block on disk
- dirty file cache data (in 2.2 only)
- shrunk by shrink_mmap()
- kernel memory
- cannot be swapped out
- used for
- task struct / kernel stack
- page tables
- slab cache
(page 30)
Linux VM 2.2: try_to_free_pages
- do_try_to_free_pages()
- first, free unused kernel memory
- in a loop, until enough pages are freed
- shrink_mmap
- shm_swap
- swap_out
- one last shrink_mmap, if needed
- swap_out()
- walks the virtual memory of all processes
- if it finds a page not accessed since last scan
- swap out the page and exit
- shrink_mmap()
- walks the page and buffer cache pages
- if it finds a page not accessed since last scan
- if the page is dirty, queue it for IO
- if the page is clean, free it and exit
You can read the functions in mm/vmscan.c and mm/filemap.c
(page 31)
Linux 2.2 VM: strong / weak points
- strong points
- simple
- relatively low overhead for most situations
- works well most of the time
- weak points
- doesn't take relative activity of different caches into account
- eg. unused shared memory segments and heavily used page cache
- simple NRU replacement makes us copy too many pages to/from highmem
- accessed clean pages sometimes get evicted before old dirty pages
- NRU replacement breaks when all pages were accessed (because \
we haven't scanned memory in a long time)
- doesn't work well under wildly varying VM load
- easily breaks down under very heavy VM load
(page 32)
Linux VM: changes in 2.4
- balanced page aging
- smarter page flushing
- make VM more robust under heavy loads
- drop-behind for streaming IO and file writes
- not (yet) supports mmap and friends
Not yet in 2.4 as of september 2000
- page->mapping->flush() callback
- journaling, phase tree or soft update filesystems
- page flushing for bufferless (network?) filesystems
- pinned buffer reservations
- for journaling, etc. filesystems
- write throttling for everything
- currently only works for generic_file_write and friends
(page 33)
Linux VM: 2.4 / 2.5 page aging
- balanced page aging
- mapping/unmapping pages takes overhead, so we want few inactive pages
- however, more inactive pages results in better page replacement
- the solution is a dynamic inactive target
- separate page aging and page flushing
- page aging is done the same on dirty and clean pages
- the "lazy flush" optimisation is only done for old pages
- page pages from all caches on the same queue
- physical page based page aging
- requires physical -> virtual reverse mappings
- fixes balancing issues
- big change, to be done for 2.5
- do light background scanning
- no half-hour old referenced bits lying around
- better replacement with load spike after quiet period
(page 34)
Linux VM: multiqueue VM
- multiple queues used to balance page aging and flushing
- active
- pages are in active use, page->age > 0 or mapped
- page aging happens on these pages
- inactive_dirty
- pages not in active use, page->age == 0
- pages that might be(come) reclaimable
- dirty pages
- buffer pages
- pages with extra reference count
- cleaned in page_launder(), moved to inactive_clean list
- inactive_clean
- pages not in active use, page->age == 0
- pages which are certainly immediately reclaimable
- can be reclaimed directly by __alloc_pages
- keep data in memory as long as possible
(page 35)
Linux VM: balancing aging and flushing
- static free memory target
- free + inactive_clean > freepages.high
- enforced by kswapd
- if free memory is too low, allocations will pause
- dynamic inactive memory target
- free + inactive_clean + inactive_dirty > freepages.high + inactive_target
- enforced by kswapd
- page flush target
- free + inactive_clean > inactive_dirty
- enforced by bdflush / kflushd
- memory_pressure / inactive_target
- one-minute floating average of page replacements
- in __alloc_pages and page_reclaim, memory_pressure++
- in __free_pages_ok, memory_pressure--
- memory_pressure is decayed every second
- inactive_target is one second worth of memory pressure
(page 36)
Linux 2.4 VM: try_to_free_pages
- do_try_to_free_pages()
- work towards free target
- kmem_cache_reap()
- page_launder()
- work towards free and inactive target
- refill_inactive()
- basically the old try_to_free_pages() with page aging
- has the same balancing issues as 2.2
- shrink_mmap() is gone (wooohooo)
- in 2.5, replace with physical page based aging
- moves pages to the inactive list instead of freeing them
(page 37)
Linux 2.4 VM: page_launder
- moves clean, unmapped pages from inactive_dirty to inactive_clean list
- flushes dirty pages to disk, but only if needed
- pass 1
- move accessed or mapped pages back to the active list
- move clean, unmapped pages to inactive_clean list
- free clean buffercache pages
- if there is enough free memory after pass 1, stop
- pass 2 (launder_loop, clean dirty pages)
- start async IO on up to MAX_LAUNDER pages
- start synchronous IO on a few pages, but only if we failed to free any
page in pass 1
- this function is so complex because
- we do not want to start disk IO if it isn't needed
- we do not want to wait for disk IO
- we do not want to start too much disk IO at once
(page 38)
Linux VM: flush callback & pinned pages
- page->mapping->flush(page)
- give filesystems more freedom for own optimisations
- IO clustering
- allocate on flush / lazy allocate
- advisory call, filesystem can write something else instead
- write ordering of journaling or phase tree fs
- not flush the page now because of online fs resizing, etc
- pages no longer depend on the buffer head
- allocate on flush
- can use other data structures (kiobuf)
- abstract away page flushing from VM subsystem
- pinned reservations for journaling filesystems
- sometimes need extra pages to finish a transaction
- having too many pinned pages screws up page replacement
- write ordering constraints
(page 39)
Linux VM: plans for 2.5
- physical page based aging & equal aging of all pages
- improved IO clustering and readahead
- anti-thrashing measures (process suspension?)
- pagetable sharing
- (maybe) page table swapping
- large page sizes
- NUMA scalability
(page 40)
Linux VM: plans for 2.5
- physical page based aging
- virtual scanning based page aging has some "artifacts"
- aging all pages equally fixes the balancing issues
- requires physical -> virtual reverse mappings
- improved IO clustering and readahead
- better IO clustering reduces disk seeks a lot
- explicit IO clustering for swapout
- readahead and read clustering on the VMA level
- drop-behind for streaming mmap() and swap
- anti-thrashing measures
- the system only supports up to some limit of VM load
- if more processes are running, the system slows to a halt
- solution
- temporarily suspend one or more of the processes
- the VM subsystem can keep up with the remaining load
- suspend / resume the processes in turn, for fairness
(page 41)
Linux VM: more plans for 2.5
- pagetable handling improvements
- at the moment, page tables are
- unswappable
- unfreeable (until process exit)
- up to 3MB per process
- we want to reduce this overhead
- (COW) page table sharing
- page table destruction / swapping
- large page sizes
- some architectures have "variable" page sizes
- Linux needs to have some code changed to support this right
- NUMA (and SMP) scalability
- NOT about finer grained locks, that won't work
- move currently global variables and structs to the per-node struct pgdat
- look into using more (per-cpu?) local structures
- look into making code paths lock-less
(page 42)
Linux VM: OOM / QoS
- when the system goes OOM (out of memory), kill a process
- don't kill system-critical programs
- lose the minimal amount of work
- recover the maximum amount of memory
- never kill programs with direct hardware access
- Linux overcommits memory, processes can reserve more memory than what's
available
- this is very efficient
- but sometimes goes wrong
- it might be good to give people a choice about this ;)
- Quality of Service issues
- fairness between users and/or groups of users
- different users with different priorities
- in case of overcommit, take user VM usage into account for OOM killing
(page 43)
Acknowledgements
Thanks go out to
- DEC, from who I stole the "pyramid" picture
- CMU, where I got the other picture
- David Olivieri, who helped improve this slides
- Linus Torvalds, for giving us lots of work to do
Links
- Linux-MM
- http://www.linux.eu.org/Linux-MM/
- VM Tutorial
- http://cne.gmu.edu/modules/VM/
- Design Elements of the FreeBSD VM System
- http://www.daemonnews.org/200001/freebsd_vm.html
- My home page, where you can download these slides
(page 44)